日本語から英語への機械翻訳やIMEにおける変換予測など、人の言葉を機械で処理する学術分野は自然言語処理(NLP:Natual Language Processing)と呼ばれている。Deep LearningはNLPの分野においても応用可能であり、RNN(回帰型ニューラルネットワーク:Recurent Nural Network)を利用して英仏の機械翻訳するという試みではよい結果を残している(
*1)。
これらの場合、RNNへの入力データは翻訳文章そのものではなく、文章内の単語をベクトル化(Word2Vec)した「word embeding」の配列を利用する。この「word embeding」は単なる単語ではなく、単語の意味やどのような文脈で利用される単語かという情報を持つことができる。近年の自然言語処理分野では重要な技術の一つである。もちろん、Deep Learningで機械翻訳などのNLPを行う際にも、このWord2Vecの技術は重要である。
というわけで、今回はWord2Vecの概要とDeepLearning4jで利用する方法について確認する。ちなみにWord2Vec自体はDeep Learningの一手法というわけではない。
■ 単語をベクトル化する(Word2Vec)とは?
Word2VecはTomas Mikolovらのチーム(Google社)が2013年に発表した単語を高次元のベクトル(word embeding)に変換する手法である(
*2,
*3,
*4)。Word2VecではNNLM(Nural Network Language Model)と呼ばれる考え方を利用しており、ニューラルネットワークを利用して単語→word embedingの変換を計算する。
単語をword embedingに変換して嬉しいことは、word embedingには単語で表せない意味合い等の情報を持たせることができることである。自然言語の単語で例えて考えると、「リオ(リオデジャネイロ)」という単語と「レオ(ライオン)」という単語は1文字しか違わない。だからといって意味が近い単語とは言うことができないように、単語を表す文字列には意味の情報が乏しいため、コンピュータが単語だけから2つの単語の意味が似ているかどうかを理解することは難しい。
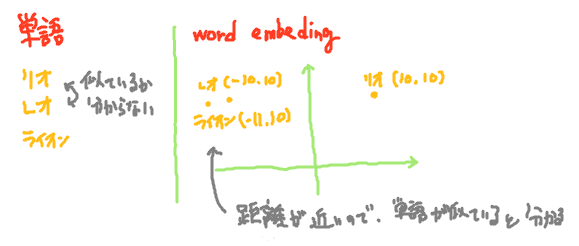 図:単語空間とword embeding空間のイメージ
図:単語空間とword embeding空間のイメージ
ここで新しい考え方として、2次元のベクトル空間を作成し意味合いが近い単語の距離が短くなるように単語をマッピングすることを考える。例えば「リオ」は(10,10)、「レオ」は(-10,10)のように単語を2次元座標に対応付ける。意味合いが近い言葉の距離が短くなるようにしたいため、「レオ」に意味合いが近い別の単語「ライオン」を考えると、「レオ」の近くの座標(例えば(-11,10))にマッピングされることになる。このように単語がマッピングできると、コンピュータは単語の意味の近さを2次元ベクトル空間内の距離の近さとして計算できるため、「レオ」は「リオ」よりも「ライオン」に近いと認識できるようになるのである。このマッピングされた点をword embedingと呼ぶ。word embedingはベクトルとして表現され、実際には2次元よりももっと高次元のベクトルとして表現される。
単語をマッピングしたこのベクトル空間ではword embedingの距離が意味の差に等しくなるようで、word embedingに加算・減算が定義できるようになっている。過去の論文では「king - man + woman」という計算を行うと「queen」という単語が計算されたという結果も報告されている(
*3)。これは「king」と「man」の距離の差がそのまま「統治者」とか「王」という意味の差になり、「woman」にこの距離を足し合わせた「king - man + woman」の計算結果は「女性の統治者」とか「女性の王」という意味の「queen」となったためと考えられる。
図:word embeding「king」「man」「woman」「queen」の位置関係のイメージ
上記のように単語に意味などの情報が付加したword embedingが機械翻訳などで利用しやすい情報であることは何となく想像できると思われる。しかし、word embedingを人の手で計算することはとても難しいため、Word2Vecでは単語→word embedingの変換をニューラルネットワークを利用して計算しているのである。
■ Word2Vecの技術的な概要
Word2Vecによって単語→word embedingの変換を計算するしくみはあまり難しくはない。計算には以下の3層のニューラルネットワークを利用する。プロジェクション層、出力層はともに全結合層で構成するため、全体としては多層パーセプトロンそのものである。
このニューラルネットワークでは、プロジェクション層で単語をword embedingに変換(出力)し、word embedingを出力層で評価、変換結果が芳しくない場合には誤差逆伝搬法により変換パラメータを更新するという処理を行う。
図:Word2Vecにおいて、word embedingへの変換行列を計算するために利用するニューラルネットワーク
入力層
入力では単語を表す1-hot-vectorを入力とする。1-hot-vectorとは、特定の要素が1それ以外が0のベクトルのことである。Word2Vecの場合、語彙数(利用可能な単語の総数)\(V\)個の要素を持つベクトルで、単語を表すインデックスの要素だけが1という値を持つ。例えば語彙が「I」「am」「Tom」「.」の4つで、「I」=0、「am」=1、「Tom」=2、「.」=3のように単語にインデックスを対応付けた場合には、「am」を表す1-hot-vectorは\((0,1,0,0)\)のように表現される。
プロジェクション層
プロジェクション層では入力ベクトルをword embedingに変換する。プロジェクション層には活性化関数を設定しない。いま、入力ベクトルを\(\mathbf{x}\)、プロジェクション層のニューロン数を\(N\)、各ニューロンの重みを集めた重みベクトルを\(\mathbf{W}\)とすると、プロジェクション層の各ニューロンの出力\(\mathbf{h}\)は以下の式で表される。
\begin{align*}
\mathbf{h} & = \mathbf{x} \mathbf{W} \\
& = (x_1,x_2,\cdots,x_V)
\begin{bmatrix}
w_{11} & w_{12} & \cdots & w_{1N} \\
\vdots & \vdots & \vdots & \vdots \\
w_{V1} & w_{V2} & \cdots & w_{VN} \\
\end{bmatrix}
\end{align*}
一見難しい計算に見えるが、入力ベクトル\(\mathbf{x}\)が1-hot-vectorであることを考慮すると、入力が\(i\)番目の単語の場合\(i\)行目以外の値はすべて0をかけることが分かる。結果、計算は以下のようにプロジェクション層の重み行列\(\mathbf{W}\)の\(i\)行目を抜き出す処理に等しくなる。
\begin{align*}
\mathbf{h} & = \mathbf{x} \mathbf{W} \\
& = (0,\cdots,1,\cdots,0)
\begin{bmatrix}
w_{11} & w_{12} & \cdots & w_{1N} \\
\vdots & \vdots & \vdots & \vdots \\
w_{V1} & w_{V2} & \cdots & w_{VN} \\
\end{bmatrix}\\
& = (w_{i1},w_{i2},\cdots,w_{iN})
\end{align*}
Word2Vecでは重みベクトル\(\mathbf{W}\)を単語→word embedingの変換行列とみなし、プロジェクション層の出力をベクトル化した\(\mathbf{h}\)がword embedingとなる。
出力層
出力層では、プロジェクション層の重みベクトル\(W\)が適切な単語→word embeding変換を学習するように評価する必要がある。ここでいう評価とは、単語の意味が似ている2つの入力ベクトル\(\mathbf{x_1},\mathbf{x_2}\)に対して、プロジェクション層の出力ベクトル\(\mathbf{h_1},\mathbf{h_2}\)が似たような値をとっているかを測定することである。
では、『単語の意味が似ている』とはどういうことだろうか。定義の方法はいくつかあると思うが、Word2Vecにおいては『単語の意味合いが近い場合、その単語の前後には同じような単語が出現する』という仮説を立てている。例えば「I love penguins」「You love penguins」という二つの文があった場合、「I」と「You」は「love penguin」が続くことから似ていると判断する。実際「I」と「You」は人を指す代名詞であるため、この仮説はある程度は正しいということができると思われる。
いま教師データとして\(n\)個の単語で構成された文章\(\mathbf{s}=(\mathbf{x_1},\mathbf{x_2},\cdots,\mathbf{x_n})\)(※\(\mathbf{s}\)の各要素は単語を表す1-hot-vector)を考える。ニューラルネットワークは\(j\)番目の単語\(\mathbf{x_j}\)が入力となった場合、出力が\(\mathbf{x_{j+1}}\)や\(\mathbf{x_{j-2}}\)といった周辺の単語となるよう他クラス分類を解くように構成すればよい。このように学習すると、単語の意味が似ている2つの入力ベクトル\(\mathbf{x_1},\mathbf{x_2}\)に対して出力(次に出力される単語)が同じ値となるため、その途中の計算結果であるプロジェクション層の出力ベクトル\(\mathbf{h_1},\mathbf{h_2}\)も似たような値をとることが期待できる。実際には入力\(\mathbf{x_j}\)に対して、入力単語の前後\(R\)個(2~5個程度)の単語\(\mathbf{x_{j-R}}\)~\(\mathbf{x_{j+R}}\)が出力になるように学習する。
上記のような理由から、出力層ではニューロンの数を単語総数\(V\)、活性化関数にソフトマックス関数を利用して、入力単語の周辺で出現する単語を出力するよう構成する。学習方法としては、誤差逆伝搬法で誤差関数は確率的勾配降下法、学習世代は3、学習率0.025を設定するのがよいなど、設定の詳細は元論文(
*3)参照のこと。ちなみに、日本語では
*5の方が数式計算を詳しく解説されている。
その他
出力層で『単語の意味合いが近い場合、その単語の前後には同じような単語が出現する』という仮説を置いたが、この仮説を実装する方法には以下の2種類が存在する。すなわち、『文脈から現在の単語を推測する(CBOW))』か『現在の単語から文脈を推測する(skip-gram)』かである。2者は入力と出力の関係が逆転しただけの関係であるが、精度的にはSkip-gramのほうがよいという結果が出ている。
- continuous bag-of-words (CBOW) …前後の単語(文脈)から、現在の単語を推測
- continuous skip-gram…現在の単語から、前後の単語(文脈)を推測。
また、前述したようにWord2VecはNNLMという考えに基づいている。Word2Vecの素晴らしいところは、他のNNLMで存在する隠れ層をなくし、プロジェクション層をすべての入力で共有したことによって、学習による計算量を劇的に少なくすることに成功したことである。利用する単語数(ボキャブラリ)\(V\)は、場合によっては億単位にまで上ることがある。これに対して、従来のNNLM手法では計算量が\(O(V)\)であったが、Word2Vecでは\(O(\log_2V)\)に削減されている。Skip-gramについては計算量の少なさだけでなく、word embedingの精度まで上回ったと報告されている。
■ DeepLearning4jでWord2Vecを利用する
DeepLearning4jでWord2Vecを利用する際には、以下のクラスを利用する。DeepLearning4jではSkip-Gramが実装されている。利用例はサンプルプログラムを参照のこと。
| クラス |
内容 |
| Word2Vec |
Word2Vecを行うメインクラス |
SentenceIterator
DocumentIterator |
Word2Vecに入力データを渡すクラス。文章ファイルなどから文章を1つずつ取得する。可能な限りSentenceIteratorを利用するべきとのこと。 |
Tokenizer
TokenizerFactory |
SenetenceIterator等で取得した文章を単語に分割するクラス。 |
| VocabCache |
単語の数や出現率、単語の連続性などを保持するクラス。
学習後のWord2Vecから取得可能。 |
| Inverted Index |
単語の出現率などを保持。Lucene indexなども自動的に作成する。 |
■ サンプルプログラム1(word embedingの作成)
以下にDeeplearning4jでWord2Vecを利用するサンプルプログラムを示す。以下のサンプルはDeeplearning4jのチュートリアルを参考にして作成した。サンプルでは1行ごとに英語の文章が記述されたファイル「raw_sentences.txt」内の単語をword embedingに変換するWord2Vecインスタンスを作成し、「people」と「money」のword embedingの距離や、「day」に似た単語を出力している。
◇リソース
dl4j-tutorial(プロジェクトフォルダ)
┣ src/main/java
┃ ┗ Word2VecTest1.java
┣ input
┃ ┗raw_sentences.txt(
ココから取得)
┗ output
◇サンプルプログラム
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import org.deeplearning4j.models.embeddings.loader.WordVectorSerializer;
import org.deeplearning4j.models.word2vec.Word2Vec;
import org.deeplearning4j.text.sentenceiterator.LineSentenceIterator;
import org.deeplearning4j.text.sentenceiterator.SentenceIterator;
import org.deeplearning4j.text.sentenceiterator.SentencePreProcessor;
import org.deeplearning4j.text.tokenization.tokenizer.TokenPreProcess;
import org.deeplearning4j.text.tokenization.tokenizer.preprocessor.EndingPreProcessor;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.deeplearning4j.text.tokenization.tokenizerfactory.TokenizerFactory;
/**
* DeepLearning4jでWord2Vecを行うサンプルプログラム
* @author karura
*/
public class Word2VecTest1
{
public static void main(String[] args) throws IOException
{
// コーパス(文章集)データの読み込み
// 読み込み時に文字をすべて小文字に変換する
System.out.println( "Load data..." );
File f = new File( "input/raw_sentences.txt" );
SentenceIterator ite = new LineSentenceIterator( f );
ite.setPreProcessor( new SentencePreProcessor()
{
@Override
public String preProcess( String sentence ){ return sentence.toLowerCase(); }
});
// 文章を単語に分解
// 分解時に単語を小文字に、半角数を"d"に変換する
System.out.println( "Tokenize data..." );
final EndingPreProcessor preProcessor = new EndingPreProcessor();
TokenizerFactory tokenizer = new DefaultTokenizerFactory();
tokenizer.setTokenPreProcessor( new TokenPreProcess()
{
@Override
public String preProcess( String token )
{
token = token.toLowerCase();
String base = preProcessor.preProcess( token );
base = base.replaceAll( "\\d" , "d" );
return base;
}
});
// モデル作成
System.out.println( "Build model..." );
int batchSize = 1000; // 1回のミニバッチで学習する単語数
int iterations = 3;
int layerSize = 150;
Word2Vec vec = new Word2Vec.Builder()
.batchSize( batchSize ) // ミニバッチのサイズ
.minWordFrequency( 5 ) // 単語の最低出現回数。ここで指定した回数以下の出現回数の単語は学習から除外される
.useAdaGrad( false ) // AdaGradを利用するかどうか
.layerSize( layerSize ) // 単語ベクトルの次元数。
.iterations( iterations ) // 学習時の反復回数
.learningRate( 0.025 ) // 学習率
.minLearningRate( 1e-3 ) // 学習率の最低値
.negativeSample( 10 ) //
.iterate( ite ) // 文章データクラス
.tokenizerFactory(tokenizer) // 単語分解クラス
.build();
// 学習
System.out.println( "Learning..." );
vec.fit();
// モデルを保存
System.out.println( "Save Model..." );
WordVectorSerializer.writeWordVectors( vec , "output/words.txt" );
// 評価1(二つの単語の類似性)
// コサイン距離
System.out.println( "Evaluate model..." );
String word1 = "people";
String word2 = "money";
double similarity = vec.similarity( word1 , word2 );
System.out.println( String.format( "The similarity between 「%s」 and 「%s」 is %f" , word1 , word2 , similarity ) );
// 評価2(ある単語に最も意味が近い言葉)
String word = "day";
int ranking = 10;
Collection<String> similarTop10 = vec.wordsNearest( word , ranking );
System.out.println( String.format( "Similar word to 「%s」 is %s" , word , similarTop10 ) );
}
}
◇実行結果
Load data...
Tokenize data...
Build model...
03:01:04.530 [main] DEBUG org.nd4j.nativeblas.NativeOps - Number of threads used for linear algebra 1
…中略…
Save Model...
03:29:28.457 [main] INFO o.d.m.e.loader.WordVectorSerializer - Wrote 236 with size of 150
Evaluate model...
The similarity between 「people」 and 「money」 is 0.162286
Similar word to 「day」 is [week, night, year, game, season, percent, dur, time, office, former]
dur 0.03706284239888191 -0.3273228108882904 -0.02901708
been 0.07721598446369171 -0.3042716383934021 -0.1655066…
year -0.04181159287691116 -0.28206467628479004 -0.20906…
about -0.3287375867366791 0.03922347351908684 0.0778141…
your -0.2562347650527954 0.08040153235197067 0.49649453…
without -0.3843825161457062 -0.43209001421928406 0.1945…
these 0.359978586435318 -0.2246623933315277 0.170168146…
music -0.09605858474969864 -0.22566641867160797 -0.4158…
…
◇解説
Word2Vecインスタンスは、SentenceIterator(26行目~33行目で作成)とTokenizerFactory(37行目~50行目で作成)を指定して作成する。インスタンス作成後は、他のニューラルネットワークの場合と同様、fit関数により学習を実施する(73行目)。注意点としては、word embedingをファイルに保存するにはWordVectorSerializer::writeWordVectorsという専用のクラスを利用する必要がある点である(77行目)。
学習後はword embedingを利用した計算が可能で、84行目で「people」と「money」という単語のword embedingに対して距離(意味合いの類似度)を計算したり、90行目では「day」という単語との類似度が高いトップ10の単語を取得したりしている。
■ サンプルプログラム2(word embedingの加算・減算)
以下にDeepLearning4jでword embedingの加算と減算を行うサンプルプログラムを示す。サンプルでは、サンプルプログラム1で作成したword embedingをファイルから読込み、「i + you」という加算や、「companey - money」という減算を行っている。
◇リソース
dl4j-tutorial(プロジェクトフォルダ)
┣ src/main/java
┃ ┗ Word2VecTest2.java
┣ src/main/java/fastfix
┃ ┗
WordVectorSerializerFastFix.java(dl4jライブラリ(ver0.4-rc3.10)のバグを応急修正したソース)
┗ output
┗ words.txt(サンプルプログラム1で作成したファイル)
◇サンプルプログラム
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
import org.deeplearning4j.models.embeddings.wordvectors.WordVectors;
import fastfix.WordVectorSerializerFastFix;
/**
* DeepLearning4jでWord2Vecを行うサンプルプログラム
* @author karura
*/
public class Word2VecTest2
{
public static void main(String[] args) throws IOException
{
// 単語ベクトルの読込
System.out.println( "Load vectors..." );
File f = new File( "output/words.txt" );
//WordVectors vec = WordVectorSerializer.loadTxtVectors( f ); // ライブラリにバグあり
WordVectors vec = WordVectorSerializerFastFix.loadTxtVectors( f );
// 利用可能な単語を出力
Collection<String> words = vec.vocab().words();
System.out.println( "利用可能な単語" );
for( String word : words ){ System.out.println( " " + word ); }
// 単語の足し算
System.out.println( "単語の足し算" );
List<String> positiveList = Arrays.asList( "i" , "you" );
List<String> negativeList = new ArrayList<String>();
Collection<String> nearestList = vec.wordsNearest( positiveList , negativeList , 10 );
System.out.println( String.format( "%s = %s" , String.join( " + " , positiveList )
, nearestList ) );
// 単語の足し算・引き算
System.out.println( "単語の足し算・引き算" );
positiveList = Arrays.asList( "company" );
negativeList = Arrays.asList( "money" );
nearestList = vec.wordsNearest( positiveList , negativeList , 10 );
System.out.println( String.format( "%s - %s = %s" , String.join( " + " , positiveList )
, String.join( " + " , negativeList )
, nearestList ) );
}
}
◇実行結果
Load vectors...
02:28:00.367 [main] DEBUG org.nd4j.nativeblas.NativeOps - Number of threads used for linear algebra 1
02:28:00.376 [main] DEBUG org.nd4j.nativeblas.NativeOps - Number of threads used for linear algebra 1
…中略…
利用可能な単語
dur
been
year
about
your
without
these
…中略…
単語の足し算
i + you = [you, i, we, they, west, former, him, she, $, he]
単語の足し算・引き算
company - money = [company, group, director, man, very, team, general, university, fami, program]
◇解説
事前にファイル出力したword embedingを読込には、WordVectorSerializer::loadTxtVectors関数を利用する(23行目)。(dl4jライブラリver0.4-rc3.10では、この関数内にバグがある模様で常に例外が発生する。このため、今回は応急修正したソース「WordVectorSerializerFastFix.java」を利用している。)
word embedingの加算・減算にはWordVectors::wordsNearest関数を利用する(32行目~46行目)。第一引数に加算する単語、第二引数に減算する単語、第三引数に計算結果の候補を可能性の高いものから何番目まで取得するかを指定する。
■ サンプルプログラム3(word embedingの可視化)
以下にDeepLearning4jでword embedingを可視化するサンプルプログラムを示す。word embedingは高次元ベクトルであるためそのままでは可視化できないが、サンプルではt-SNE(
*8)という手法によって描画可能な次元(2次元)にベクトルをマッピングして描画している。t-SNEは高次元ベクトルの描画を目的とした次元圧縮手法で、Laurens van der Maaten(Tilburg Univer sity(蘭))が2008年に提唱した。t-SNEでは高次元ベクトルのデータ構造(クラスター等)を残しつつ低次元ベクトルにマッピングできるため、データ構造が把握しやすいという特性を持つ。
サンプルでは、サンプルプログラム1で作成したword embedingを、t-SNEによって2次元空間にマッピングしている。マッピングした内容はタブ区切りCSVとして出力されるため、excelやgnuplot等のツールによってプロットの作成が容易となっている。
◇リソース
dl4j-tutorial(プロジェクトフォルダ)
┣ src/main/java
┃ ┗ Word2VecTest3.java
┣ src/main/java/fastfix
┃ ┗
WordVectorSerializerFastFix.java(dl4jライブラリ(ver0.4-rc3.10)のバグを応急修正したソース)
┗ output
┗ words.txt(サンプルプログラム1で作成したファイル)
◇サンプルプログラム
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import org.deeplearning4j.models.embeddings.inmemory.InMemoryLookupTable;
import org.deeplearning4j.models.embeddings.wordvectors.WordVectors;
import org.deeplearning4j.plot.BarnesHutTsne;
import org.nd4j.linalg.api.ndarray.INDArray;
import fastfix.WordVectorSerializerFastFix;
/**
* DeepLearning4jでWord2Vecを行うサンプルプログラム
* @author karura
*/
public class Word2VecTest3
{
public static void main(String[] args) throws IOException
{
// 単語ベクトルの読込
System.out.println( "Load vectors..." );
File f = new File( "output/words.txt" );
//WordVectors vec = WordVectorSerializer.loadTxtVectors( f ); // ライブラリにバグあり
WordVectors vec = WordVectorSerializerFastFix.loadTxtVectors( f );
// 利用可能な単語を取得
Collection<String> words = vec.vocab().words();
// 単語とベクトル表現を出力
System.out.println( "単語とそのベクトル表現" );
Iterator<String> ite = words.iterator();
while( ite.hasNext() )
{
// 単語と単語ベクトルを取得
String word = ite.next();
INDArray vector = vec.getWordVectorMatrix( word );
// 標準出力に出力
System.out.println( String.format( "%s : %s : %s " , word
, vec.wordsNearest( vector , 5 )
, vector ) );
}
// t-SNEを利用して、2次元の表に単語をプロット
System.out.println( "ploting..." );
BarnesHutTsne tsne = new BarnesHutTsne.Builder()
.theta(0.5)
.learningRate(500)
.setMaxIter(1000)
.build();
InMemoryLookupTable table = (InMemoryLookupTable) vec.lookupTable();
List<String> list = new ArrayList<String>( vec.vocab().words() );
tsne.plot( table.getSyn0() , 2 , list , "t-SNE-plot.csv" );
}
}
◇実行結果
18483.431640625 -1694.8656005859 dur
-7451.63671875 -6846.0444335938 been
3224.25390625 -14590.3095703125 year
542.904296875 -3857.8513183594 about
-7926.5673828125 10782.16796875 your
…
◇解説
t-SNEを利用するにはBarnesHutTsneクラスを利用する。BarnesHutTsne::plot関数にプロットするword embedingと圧縮後の次元数、word embedingに対応する単語、ファイル出力先をしていすることで、タブ区切りcsvファイルが出力される。出力されたcsvファイルを元に作成したプロットが以下である。
図:「t-SNE-plot.csv」をgnuplotを用いてプロットした結果
学習する語彙が少ないためか今回のプロットでは明確なクラスタリングは確認できないが、プロット左部で「university」と「group」が近かったりとクラスタのようなものが見られる個所もあることが分かる。
■ 参照
- 論文「Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation」
- Wikipedia 「Word2vec」
- 論文「Efficient Estimation of Word Representations in Vector Space」
- 論文「Distributed Representations of Words and Phrases and their Compositionality」
- けんごのお屋敷 「Word2Vec のニューラルネットワーク学習過程を理解する」
- Johns Hopkins University 「Neural Networks Language Models」
- Wikipedia 「N-gram」
- 論文 「Visualizing Data using t-SNE」
1. 無題
何を参考にすればよいですか。